# Install the packages for the workshoppkgs <-c("bonsai","doParallel","embed","finetune","lightgbm","lme4","plumber","probably","ranger","rpart","rpart.plot","rules","splines2","stacks","text2vec","textrecipes","tidymodels","vetiver","remotes" )install.packages(pkgs)
Data on Chicago taxi trips
library(tidymodels)taxi
#> # A tibble: 10,000 × 7
#> tip distance company local dow month hour
#> <fct> <dbl> <fct> <fct> <fct> <fct> <int>
#> 1 yes 17.2 Chicago Independents no Thu Feb 16
#> 2 yes 0.88 City Service yes Thu Mar 8
#> 3 yes 18.1 other no Mon Feb 18
#> 4 yes 20.7 Chicago Independents no Mon Apr 8
#> 5 yes 12.2 Chicago Independents no Sun Mar 21
#> 6 yes 0.94 Sun Taxi yes Sat Apr 23
#> 7 yes 17.5 Flash Cab no Fri Mar 12
#> 8 yes 17.7 other no Sun Jan 6
#> 9 yes 1.85 Taxicab Insurance Agency Llc no Fri Apr 12
#> 10 yes 1.47 City Service no Tue Mar 14
#> # ℹ 9,990 more rows
#> # A tibble: 7,500 × 7
#> tip distance company local dow month hour
#> <fct> <dbl> <fct> <fct> <fct> <fct> <int>
#> 1 yes 0.7 Taxi Affiliation Services yes Tue Mar 18
#> 2 yes 0.99 Sun Taxi yes Tue Jan 8
#> 3 yes 1.78 other no Sat Mar 22
#> 4 yes 0 Taxi Affiliation Services yes Wed Apr 15
#> 5 yes 0 Taxi Affiliation Services no Sun Jan 21
#> 6 yes 2.3 other no Sat Apr 21
#> 7 yes 6.35 Sun Taxi no Wed Mar 16
#> 8 yes 2.79 other no Sun Feb 14
#> 9 yes 16.6 other no Sun Apr 18
#> 10 yes 0.02 Chicago Independents yes Sun Apr 15
#> # ℹ 7,490 more rows
#> # A tibble: 3 × 3
#> .metric mean n
#> <chr> <dbl> <int>
#> 1 accuracy 0.915 10
#> 2 brier_class 0.0721 10
#> 3 roc_auc 0.624 10
The ROC AUC previously was
0.69 for the training set
0.64 for test set
Remember that:
⚠️ the training set gives you overly optimistic metrics
⚠️ the test set is precious
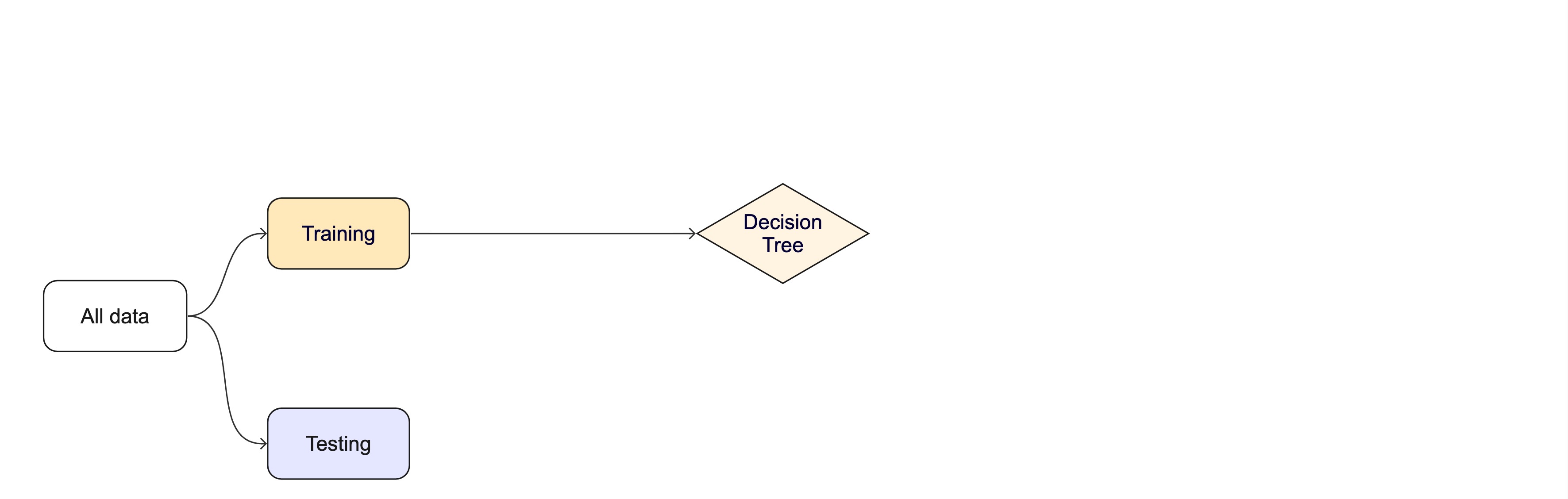
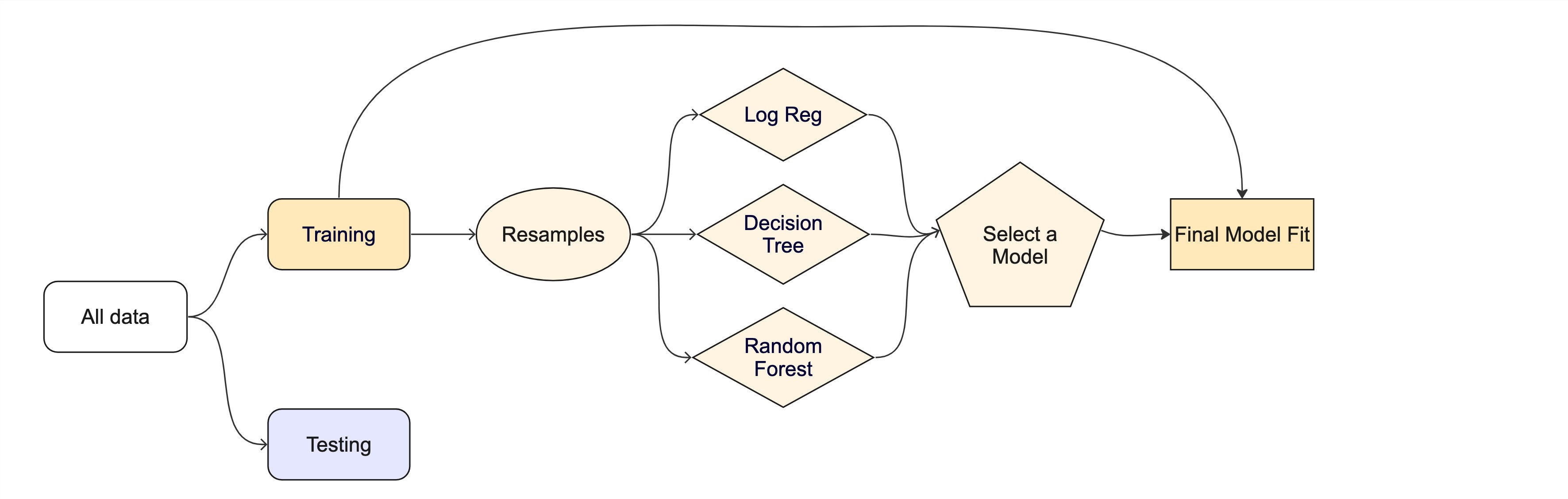
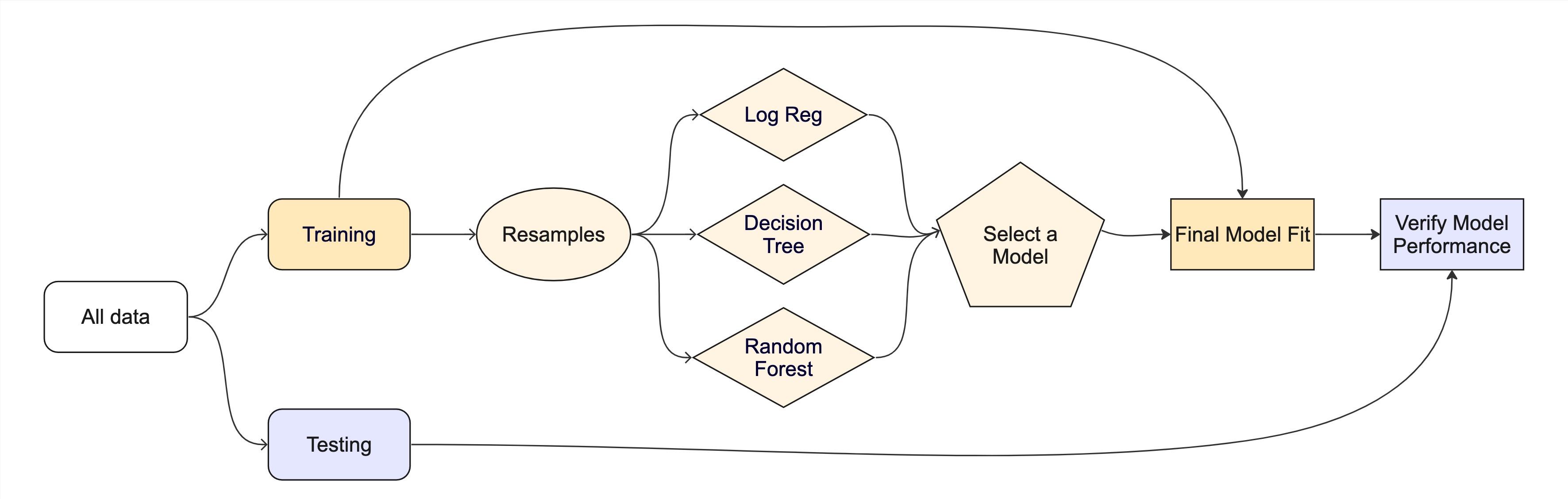
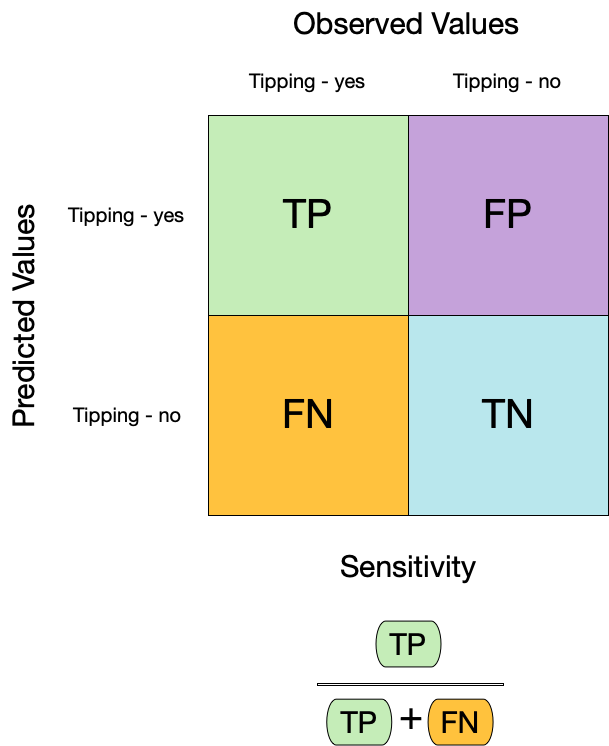
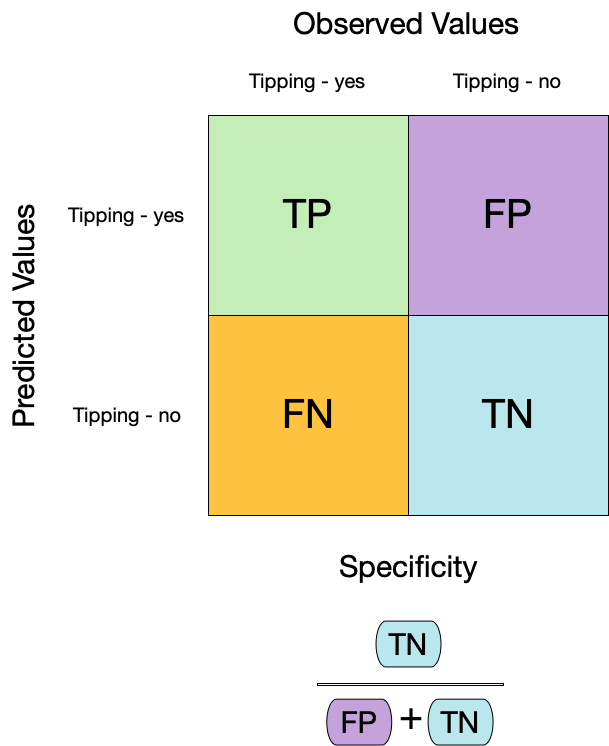
Evaluating model performance
# Save the assessment set resultsctrl_taxi <-control_resamples(save_pred =TRUE)taxi_res <-fit_resamples(taxi_wflow, taxi_folds, control = ctrl_taxi)taxi_res
#> Random Forest Model Specification (classification)
#>
#> Main Arguments:
#> trees = 1000
#>
#> Computational engine: ranger
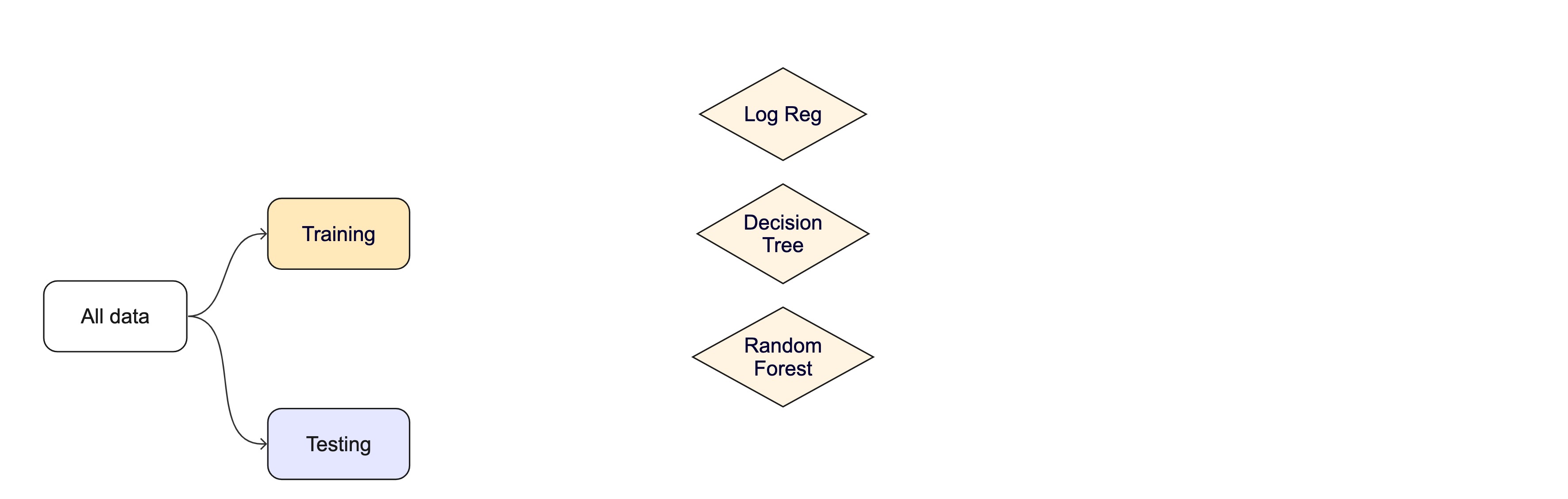
Create a random forest model
rf_wflow <-workflow(tip ~ ., rf_spec)rf_wflow
#> ══ Workflow ══════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: rand_forest()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> tip ~ .
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> Random Forest Model Specification (classification)
#>
#> Main Arguments:
#> trees = 1000
#>
#> Computational engine: ranger
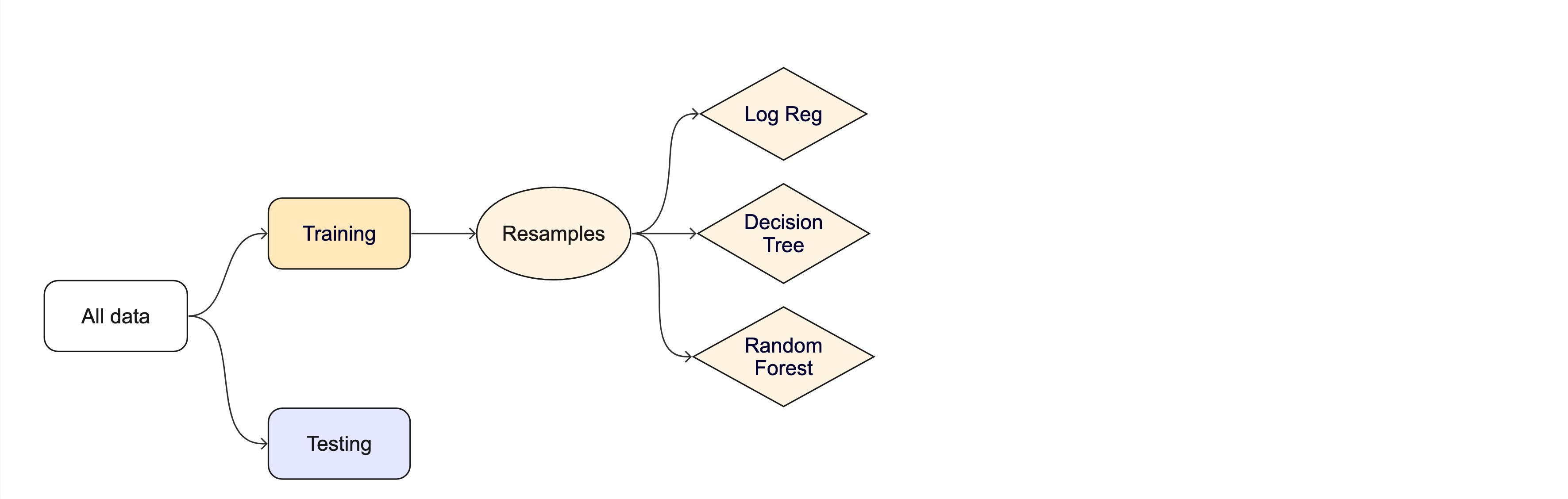
Evaluating model performance
ctrl_taxi <-control_resamples(save_pred =TRUE)# Random forest uses random numbers so set the seed firstset.seed(2)rf_res <-fit_resamples(rf_wflow, taxi_folds, control = ctrl_taxi)collect_metrics(rf_res)
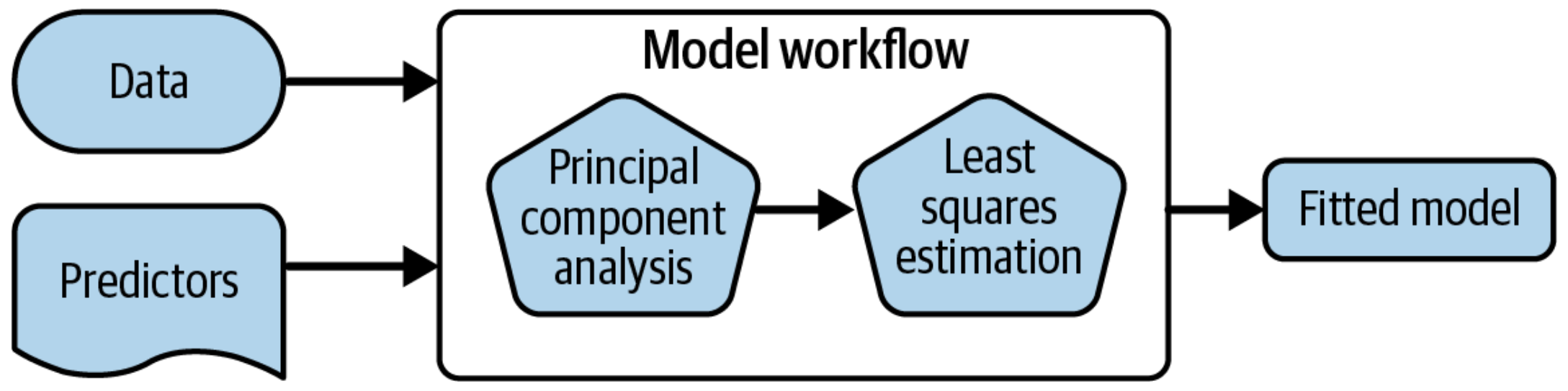
train_prediction <- xgboost_model_final |># fit the model on all the training datafit(formula = nla_formula,data = train_processed ) |># predict the sale prices for the training datapredict(new_data = train_processed) |>bind_cols( nla_train |>mutate(.obs =log10(cyanophyta)) )xgboost_score_train <- train_prediction |> yardstick::metrics(.obs, .pred) |>mutate(.estimate =format(round(.estimate, 2), big.mark =","))knitr::kable(xgboost_score_train)
test_processed <-bake(nla_recipe, new_data = nla_test)test_prediction <- xgboost_model_final |># fit the model on all the training datafit(formula = nla_formula,data = train_processed ) |># use the training model fit to predict the test datapredict(new_data = test_processed) |>bind_cols( nla_test |>mutate(.obs =log10(cyanophyta)) )# measure the accuracy of our model using `yardstick`xgboost_score <- test_prediction |> yardstick::metrics(.obs, .pred) |>mutate(.estimate =format(round(.estimate, 2), big.mark =","))knitr::kable(xgboost_score)